- ホーム
- データ活用塾
- ビッグデータ活用講座
- 第1回 問題解決方法

第1回 問題解決方法
ビッグデータの分析・活用では
PPDACサイクルを使います
ビッグデータ分析・活用は
「目的」ではありません。
問題解決のための「手段」です
 ビッグデータの分析・活用を始める前に、ひとつ確かめておきべきことがあります。それは「目的」です。他社がやっているから、新技術だから、といった動機で始めてしまっては、長続きしないでしょう。データ分析は、たいてい何らかの問題を解決するための、あくまで「手段」として用いられますが、ビッグデータも同様です。
ビッグデータの分析・活用を始める前に、ひとつ確かめておきべきことがあります。それは「目的」です。他社がやっているから、新技術だから、といった動機で始めてしまっては、長続きしないでしょう。データ分析は、たいてい何らかの問題を解決するための、あくまで「手段」として用いられますが、ビッグデータも同様です。御社の何が問題なのか、それはビッグデータで解決できるのか、どういう成果が上がれば解決とみなすのか。なぜビッグデータを用いるのか、という「目的」を事前にはっきり決めておくとよいでしょう。
PDCAなら聞いたことあるが・・・
「PPDACサイクル」とは何?
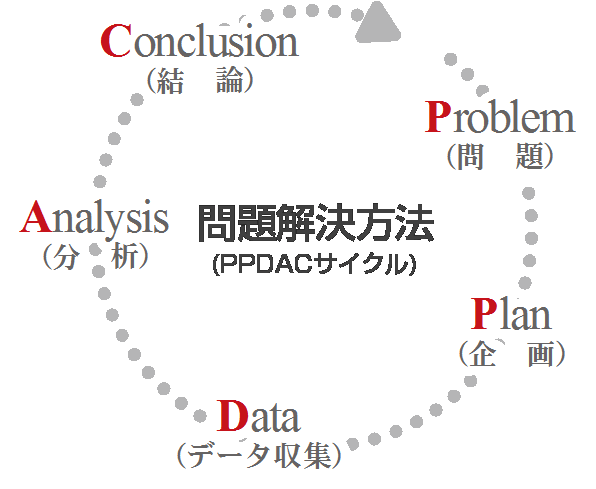 ごぞんじPDCAサイクルは、戦後日本の品質管理で用いられてきた管理手法で、Plan(計画)-Do(実行)-Check(評価)-Act(改善)という4段階からなります。PPDACサイクルとは、このPDCAを基本にしており、現代のような成熟したデータ社会における問題解決のためのフレームワークとして活用されています。Problem(問題)-Plan(計画)-Data(データ収集)-Analysis(分析)-Conclusion(結論)の5段階からなり、PDCAサイクル同様、各フェーズを循環させて繰り返すことで成果を高めることができます。
ごぞんじPDCAサイクルは、戦後日本の品質管理で用いられてきた管理手法で、Plan(計画)-Do(実行)-Check(評価)-Act(改善)という4段階からなります。PPDACサイクルとは、このPDCAを基本にしており、現代のような成熟したデータ社会における問題解決のためのフレームワークとして活用されています。Problem(問題)-Plan(計画)-Data(データ収集)-Analysis(分析)-Conclusion(結論)の5段階からなり、PDCAサイクル同様、各フェーズを循環させて繰り返すことで成果を高めることができます。PPDACサイクルの特徴は、データを活用することから、時間をかけてサイクルを回すのではなく、短時間で実行する点にあります。完璧ではなくとも、仮説的な結論をいったん出して、その結論から次の問題点を発見するという流れを作っていきます。
PPDACサイクルの
各フェーズをご説明しましょう。
① Problem(問題)何が問題になっているかを洗い出し、それらからクリアすべき「課題」を設定し、課題達成のための「指標」を決めます。「指標」は、課題をクリアできたかどうかを判断できるように、具体的で定量的な数値を定めます。
② Plan(計画)
「指標」を達成するためには、どのような調査が必要なのかを考え、調査方法を具体的に決めていきます。まず、調査方法につながるような因果関係を仮説として設定することが必要で、その後、仮説を検証するための分析手法や収集すべきデータを決めていきます。
③ Data(データの収集)
Planフェーズで決めたデータを収集し、そのデータを分析しやすいように加工します。すでに収集され社内に蓄積されたデータを使う場合もありますし、調査票のような方法であらためて収集する場合もあります。いずれにしても、最初にデータの正確性をチェックし、正確性に乏しい場合は正しいデータに加工しなければなりません。さらに、データ分析を円滑に進めるためにカテゴリー化を行うことも必要です。
④ Analysis(分析)
Dataフェーズで整理したデータをもとに分析を行い、問題解決のための施策に活用できるようなヒントを発見します。このフェーズでは、理解を促すための可視化が特に重要で、現状把握・比較・傾向などをグラフや表でわかりやすく表現すると、効率的な分析が行えます。
⑤ Conclusion(結論)
Analysisフェーズの分析結果をもとに、改善点を見つけて施策とし、仮説的ではあるが、いったん結論とします。最終結論ではないので、今回の施策を実行することで当初の課題がどのくらい改善されるのかにより、次のサイクルの問題が決まります。次のサイクルでは、新たに問題を見つけ、課題を設定し、指標を設定し…と、問題解決への歩みを止めることなく、フェーズを進めていきます。

例えば、PPDACサイクルを
コンビニにあてはめると・・・
こうなります。

とあるコンビニでは、ここのところずっと売上の減少が続いています。ならば、「問題」は売上減少で、「課題」は売上向上となります。指標としては、売上高(金額)が適切でしょう。
② Plan(計画)
コンビニの店長は、課題の売上向上を実現するための施策を考えてみました。施策の方向性としては、「新規顧客を増やす」「リピーターを増やす」「1人当たりの購入点数を増やす」などがあります。
このコンビニの品揃えは、ごく一般的で、他店との違いはありません。立地は住宅地の中ですから、新規の顧客はあまり見込めそうにありません。リピーターも今以上には増えないでしょう。

店に蓄積されたデータから、若年層・中年層・老人層・後期高齢者層でそれぞれ購入品に違いのあることが証明されれば、地域の年齢構成に合わせた品揃えにできます。あとは、住民に対してPRすれば、売上向上が見込めます。
店長の仮説のために必要なデータは、年齢(性別もあればなお良い)・購買日時・購入品名・個数・単価などです。これらのデータをクロス集計するだけで、分析可能です。
③ Data(データの収集)

POSデータが揃った段階で、各項目に矛盾がないかのチェックは必須です。さらに、年齢を年齢階級(例:20~39 / 40~59 / 60~74 / 75以上)に分類しておくと、分析がスムーズに進みます。

POSデータからは、「過去からの売上推移(全体と年齢階級別:棒グラフ)」「年齢階級別売上商品トップ10(表)」「年齢階級別 / 商品分類別売上商品トップ5(表)」「売上商品トップ10 / 売上商品トップ5の全売上高に占める割合(表)」「当該地域の年齢構成(RESAS使用:棒グラフ)」「来店者の年齢構成(棒グラフ)」などの表やグラフが出力できます。売上向上の施策に活用できるヒントを見出せれば、他にも深掘りして分析する要素は探せます。
⑤ Conclusion(結論)
店長は、地域の年齢構成を把握し、どういう年齢層が店を訪れ、どういう商品を買っていくのかを知ることができました。その分析結果を参考に、それぞれの年代に合った品揃えをすることにしました。さて、このコンビニの売上はどのくらい上がったのでしょうか…?
仮に、当初の指標よりも売上の伸びが下回ったとしても、店長が気落ちすることはありません。新たな問題を見つけ、課題を設定し、指標を決めて…とPPDACサイクルを続けて回していけばいいのです。



