

【第28回】データマイニング・夜話
(その十:子供の頃わくわくした事)
コラムTOPへ戻る
|
|
|
|
|
【第28回】データマイニング・夜話 (その十:子供の頃わくわくした事) コラムTOPへ戻る |
|
| 前回では、一足飛びにデータモデリングの結果についての話まで進みましたが、また本線に戻ってデータそのものの話を続けましょう。 データマイニングの結果では、前回の話に出ました多重債務者の発見のように、そのデータから結果が白か黒かを求められる用途が結構あります。これを専門用語では、判別分析といいます。 残念ながら、実際には白か黒か完全に決着をつけることは難しく、大体はそれぞれの判定結果に次のような形容詞がつきます。 『ほぼ間違いなく、かなり、どちらかといえば、。。。』 これらの言葉の意味するところは、100%確信はないものの、そのようなデータパターンを持っていれば、だいたいこのような結果(白、黒、つまり、借金は返済する、多重債務になり自己破産する)になるだろうと言える訳です。これを専門用語では、統計的、あるいは確率論的にそういう結果になる、と言います。 社会データに対する判別分析の場合、基本的に類似のデータを持っている人は類似の行動パターンを起こす確率が高いという『暗黙の』前提に立って議論しています。 ここで注意して欲しいのは、この『暗黙の』という修飾語です。 なぜ、暗黙なのでしょうか? それは、前回も話しましたように、自然現象では現象の背後に確固とした因果関係がありますので、ある出来事(事象)が起れば、その結果こうなるというのは暗黙ではなく、明示的な関係があります。 しかし、人の行動については、必ずしもその因果関係は決定的ではありません。 例を考えてみましょう。 夏の暑い昼食時、かなり夏ばてぎみの会社員A君は、昨晩飲み過ぎて胃の調子がよくなく、おまけに金もないとしましょう。 さて、A君は昼に何を食べると思いますか? 大抵の人は、自分の過去の経験をベースにその状況から、『そば、あるいは、うどん』を食べに行ったであろうと『暗黙の内』に思うわけです。 彼も実はそのつもりで会社を出て、通りを歩いていた訳ですが新装開店のウナギ屋ができていて、当日は開店初日ということで半額サービスという立看が出ていたとしましょう。 またおいしそうなウナギのにおいと共に、呼び込みの女の子も可愛かったとしたら、ついつい入ってしまったとしたらどうでしょう。 統計学上(つまり確率論的には)かなり稀な現象が起ったわけですが、その事象(夏ばてでもウナギを食べた)が起ったのは、A君にとってはそれなりの理由があってのことなのです。 実は社会系データ、人文系データとは、このような定めなき情緒的人間の行動を測定し、判定しようとしているのです。 【データの関係性について】 さて、ここでデータの関連性について考えてみましょう。 ほとんどの場合データの関連性というとすぐ、『それは相関係数の話でしょう』と言う人がいます。 しかし、こういったワンパターンの発想しかできない人はデータマイニングをする上では、『縁なき衆生は度し難し』とでも言えましょうか。 よく誤解されているのですが、相関係数というのは、因果関係やデータ相互間の関係を示す指標ではありません。 それでは一体何なのか?と疑問に思われるかもしれません。 相関係数というのは、あるデータ値ともう一つ別のデータ値が比例関係にあるかどうか、ということを示す指標なのです。比例関係というのは、別名、『線形的な相関』ともいいます。 この線形という形容詞が実は曲者なのです。 線形というのは、直線のようにまっすぐ、という意味です。 つまり線形の相関にあるというのは、某布団会社のテレビコマーシャルにあったように、あるデータの値が『二倍』になればそれに対応して、別の値も『二倍』になり、また三倍になればまた三倍になると言うものです。 ここで、現実の世の中のことを考えてみましょう。 たとえば砂糖の100グラム入りの袋が100円だったとします。 200グラム入りの袋はいくらになるでしょうか?きっちり二倍の200円でしょうか? そうではなく、通常はそれより少し安い価格でしょう。180円ぐらいでしょう。それでは1キログラムだとすればどれ位でしょうか?1000円ではなく、多分800円ぐらいになるでしょうね。 つまりこの二つの値(砂糖の重さと価格)は正比例の関係つまり線形関係にありません。 タクシーにしても、大抵は距離に比例してメーターの料金が上がっていましたが、最近では5000円以上の運賃だと半額にします、といった会社もあるぐらいです。 一方社会系のデータではなく、自然界の現象ではどうでしょうか? 物(例えば車)の速度(スピード)と風から受ける抵抗は、速度の二乗に比例します。 つまり、速度が二倍になれば抵抗は四倍になり、速度が三倍になれば、抵抗は九倍にもなる訳です。また物を放り投げた時にできる線を放物線と言いますが、これも落下距離は時間の二乗に比例します。 結局、自然界も社会的なデータも線形の相関を持っているデータというのは、実際のところあまりないのです。 私達は、小学校からデータの散布図をみると、つい定規を当ててみて、直線を引くといったことを無意識のうちに行っているので、つい線形(直線)の関係がどこにでもあるという風に錯覚しているのです。 これは、私達人間は昼間行動しているものですから、つい夜の暗闇が怖いと思ってしまいがちですが、地球上の生物の大半は実は夜行動物なのです。 ライオンなども大抵は夜の闇夜の中で狩をするのが本来の姿です。 ネコ科のライオンは虹彩が我々と異なっていて、極端に大きく開き、ちょうど赤外線カメラの如く暗闇でも物がはっきりと見えるのです。 そうすると、真っ暗闇といっても私達が夕暮れ時に散歩を楽しむ雰囲気で、ライオンはヌーなどの草食動物を狩にでかけるというように思えます。 横道にそれましたが、世の中のデータには線形の相関のものが少ないにも拘わらず、相関係数が線形性をベースに考えているにはどうしてだと思いますか? それは、線形関係以外のデータを処理する数学的方法が今もって見つかっていない(あるいは考えられて)いないからなのです。つまり数学者がギブアップしているからです。 結局、線形の相関以外の相関があるもののデータは相関係数では表現できないのです。 さらに言えば、線形の相関以外の相関があるデータは相関係数で測定すると誤った結論を導くことになりかねません。 y = -(x - 4)**2 + 16 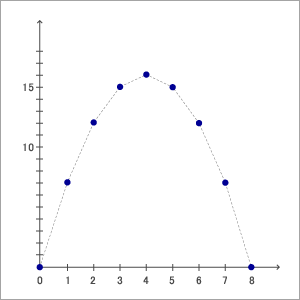 <図1:二次曲線の相関係数はゼロ > この図では、先ほど述べました放物線が描かれています。 つまり、時間と共に斜め上方に投げられた物がどういった軌跡をたどるかということを図示したものです。この図で、相関係数を求めると、なんとゼロになります。 その結果から、『横軸(時間)と縦軸(距離)の間に関係は全くない』と即断するのは間違っているのは誰の目にも明らかです。 このようにまず、データ点の集まりを定規で線を引いて当てはまりを見るというのは、極めて当てにならないことがお分かり頂けたでしょうか? 【線形性と非線形性】 ここで、ついでにデータ解析やデータマイニングでよくでてくる線形という概念およびその対立概念である非線形についてお話しましょう。 一口で言いますと、線形というのは直線です。それに対して非線形というのは曲線です。 この観点から、従来の統計解析(ここでは主に重回帰分析を指します)とデータマイニングの差を説明しましょう。 重回帰分析のデータモデリングとは、基本的に人間がデータ点を睨んで、ぐっと定規で直線を引くことと変わりありません。 それに反して、データマイニング、そのなかでも特にニューラルネットワークを使ったデータモデリングの場合は、データ点をフリーハンドで曲線的になぞっていくことに相当します。 線形のモデリングは、実データに対してどうしてうまくいかないケースが多いのかを、比喩を使って説明しましょう。 皆さんの家から近くの駅に行く事を考えてみて下さい。 地図を広げて、家と駅とを直線で結んで下さい。これが線形的解法です。 確かに直線で行けると一番早いですが、残念ながら道路はそのようにひかれていないですね。 建物や丘、林などに邪魔されて、曲がっていたり、交差していたりします。 そうすると、現実的には、そういった曲がった道を行くわけですから、駅に至る方法は何通りもありますね。その幾つかの道筋はあまり時間的にも距離的にも大差がないでしょう。 実際のデータを使ってモデリングしている時は、実はこのような状況なのです。 つまり、データ点そのものが、本来的に直線に乗っていないデータを相手にしているので、直線性をベースに考えられた従来の統計解析は実情に合わないのです。 それは、あたかも地図上で家と駅を結んだ直線道路がないのと同様です。 つまり現実のデータはそもそも非線形ですから、道路の場合のように最適な答え(最短距離の直線道路)が一つしかないのではなく、良い答え(準最適解)が幾つもあるのが一般的なのです。 本テーマである、『データの蜃気楼』はまだまだこれだけに止まりません。 |
|
続く... |
|
|
△TOPへ Copyright © 2004 Zetta Technology Inc. All rights reserved.
|
|