

【第28回】データマイニング・夜話
(その十:子供の頃わくわくした事)
コラムTOPへ戻る
|
|
|
|
|
【第28回】データマイニング・夜話 (その十:子供の頃わくわくした事) コラムTOPへ戻る |
|
| データマイニングが対象とするのは、数値データが主体です。 数値データといっても、連続値(年令、資本金、営業利益、など)もありますし、カテゴリー値(男女、職種、購入品目分類、など)があります。 現在は、テキストマイニングと称して、自然言語のテキスト文を構文解析などして、重要単語、頻出単語などを摘出して、文章の意味的解析をする手法もさかんに言われています。 とくに、化粧品などの新製品を開発するときにユーザーからの意見をその属性データや購買履歴情報と組み合わせて分析する方法が注目を集めています。 さて、その数値データですが、データが大量になると実体を把握するのに苦労します。 つまり、砂漠で蜃気楼に出会うようにデータにもいろいろと蜃気楼がまとわりついているのです。 まず、私達がデータマイニングの対象にするデータは大抵の場合、社会系データ(金融データ、クレジットヒストリー、など)、人間系データ(政治アンケート、嗜好アンケート、など)がほとんどです。 これと対照なのが物理系・化学系データ(熱伝導、電界と磁場の関係、など)です。 この二つのデータ群の違いは大変大きいものがあります。 喩えてみれば物理系・化学系のデータは無菌室での培養実験に相当し、社会系・人文系のデータは雑菌だらけの戸外での培養実験に相当すると言えるでしょう。 私の経験では、後者(社会系・人文系)のデータは、攪乱要因が多く、本来目的とするデータを純粋に取り出すことはほぼ不可能といえます。 つまり、データ自体に再現性はないことは言うまでもなく、なぜそのようなデータが得られたか?本当の要因は何か?と言った本来データ分析で当然追求すべき事柄をつきとめるには、あまりにも入手できるデータが乱雑すぎるのです。 先ほどの喩えで言うと、本来培養しようとしていた菌の他に雑菌がうようよ繁殖しているシャーレのようなものです。 この違いを認識せず、社会系データあるいは人文系データをあたかも物理系・化学系データのように論理的に扱おうとするアナリストが世の中には多いですね。 また、そういう人に限って自分の使っている手法の優位性を誇示したがるものです。 そして、あたかも、こまかく分析すればするほど、深淵な真理に到達するとでもいうような論調で、まくしたてるものです。 こうなると、蜃気楼に惑わされている、と言うよりかなり重症な精神錯乱者とでも言えるかもしれません。  <図1:2つのデータタイプ> ここで反論が聞こえてきそうですね。 『そうしたらあなたは過去のデータマイニングのプロジェクトでどのような分析をしてきたのか?』と。 私の経験上では、社会系データあるいは人文系データでのデータマイニングの分析結果はあくまでも一過性のものに過ぎない、また、その分析結果を実際に適用してみて初めて分析が正しかったのかどうかが分かる。 しかし、いくらその実際の適用で効果がでたとしても(例:売上増大、レスポンス率の向上、など)それは、因果関係を説明したことにはならない、というものです。 その理由は、社会系データあるいは人文系データでは、物理系・化学系データのように、結果に影響を与えている本当の因子を特定することはほとんど不可能であるからです。 そういった制約が潜在する社会系データでのデータマイニングではとりあえず、ある目的の傾向を示すデータ群を選別する、という観点で私はデータモデリング(予測モデルともいう)をしてきました。 具体的に言いますと、クレジットカード会社では、カード発行の申し込みを処理する業務(入会審査という)があります。現在、カード会社には、借金を多く抱えた人が急場しのぎのために金を借り入れる必要に迫られてカード発行を申し込む人が多くやってきます。 これら、多重債務者、つまり、自己破産予備軍は、カード会社にとっては、迷惑この上ない客なのです。 彼らは、カードをつくるや否や、限度額目一杯に借りまくり、暫くすると自己破産することになります。 しかし、そのような客でも必ずしも全員がすぐに自己破産する訳ではないのです。 そうすると、限度額目一杯に使ってくれる客というのは一転して、優良顧客ということになる訳です。 結局審査では、沢山キャッシングしてくれたり、ショッピングに使ってくれて、それでいて倒れそうで倒れない客を入会させることができればそれにこしたことはない訳です。 このようなテーマに対して、私が遂行したデータマイニングプロジェクトというのは、次のようなものでした。申し込み用紙に記入された、本人が申告した属性情報と、外部信用情報から、自己破産しそうな客とそうでない客を判別するものです。 分かりやすくいいますと、それらのデータをベースにすると、自己破産する割合が高い人のグループと低い人のグループに判別します。 実際には二グループというより、評点をつけるのですが、概念的には十グループ程度に分類するものと考えて下さい。 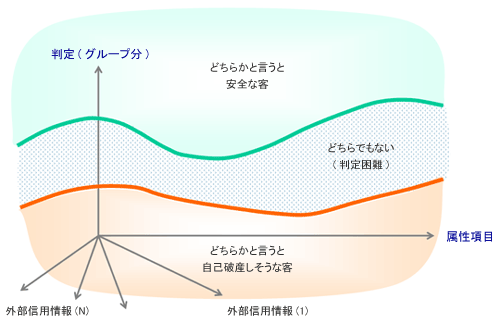 <図2:自己破産者の判定モデル> この十グループに分けた時、なぜそういった属性やデータ値をもった人が自己破産しやすいのか?という原因追求は一切行いません。 ここで言えるのは、過去のデータから、そういったデータ値をもった人は『実績ベースで』こうであった、としか言えないのです。こういった時に、もっと突っ込んだ分析をしたら、根本原因がわかるなどとは間違っても思ってはいけません。 そういった過信に陥ると、データの蜃気楼に迷わされる事になりかねません。 |
|
| 続く... |
|
|
△TOPへ Copyright © 2004 Zetta Technology Inc. All rights reserved.
|
|