

【第28回】データマイニング・夜話
(その十:子供の頃わくわくした事)
コラムTOPへ戻る
|
|
|
|
|
【第28回】データマイニング・夜話 (その十:子供の頃わくわくした事) コラムTOPへ戻る |
|
| 前回は、データの関係性について、それも特に相関関係や線形性がもたらす蜃気楼について述べました。 小学校以来何気なく使っている一番簡便な方法、つまり定規でデータ点の中心に直線を引くという行為が必ずしも適切でないこともあるということを知って皆さんは驚かれましたか? 今回も更に「えっ」と驚くようなことをお見せいたしましょう。 【あるのに、ない。ないのに、ある。】 前回お話しましたデータの相関を求めるというのは、複数の属性が混在したデータを図示した場合、うっかりすると誤った判断を下すことがあります。 図1の左図をご覧ください。これは、塩の摂取量と胃がんの発生率を図式化したものです。 先ずは男性の黒丸と女性の白丸の区別をせず全体をながめて下さい。 点の集合が円形をしていますね。 このような場合、計算するまでもなく、相関係数はかなり低い値になります。 これから、『塩の摂取量は胃がんと無関係(無相関)』と即断するのは早計です。 この場合は、例えば、男女のデータ点を分けて見てみましょう。 そうすると、それぞれの群のデータは右肩上がりのかなり強い相関があることが分かります。 つまり、このように属性が混在しているデータは層別(この場合、男女)に見ることで正しい関連が見えてくる場合がある、という例です。 また、図1の右図はこれとは逆に小2、小4、小6の本来層別に分析すべきデータを混在させたために、見かけ上相関計数が高く計算されてしまったケースです。 この場合も、データを層別にみると正しい関連(足の大きさと数学力が無相関である)ということが分かります。 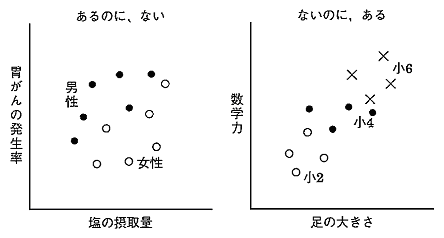 <図1:『あるのに、ない。ないのに、ある。』> (出典:『ビジネス数学のはなし』大村平著、日科技連、P.73) これらの例では、層別する観点がすぐに見つかったので、蜃気楼に惑わされずにすみましたが、実際のデータ分析では、データ項目が多い(高次元)ため、どの項目で層別するかはなかなか難しい問題です。 【正規化は魔法の杖にあらず】 次の蜃気楼は『正規化』という問題です。 正規化という言葉は普段使わないので難しそうに聞こえますが、簡単に言えば物を測定する単位の取り方のことです。 例えば、身長を測定することを考えてみましょう。長さの単位だからセンチメーターに決まっているではないか!とおっしゃるかも知れません。 しかし、別にメーターで測っても構わないし、ミリメーター、あるいは極端にはキロメーターや尺で測ってもいい訳です。つまり、実質的に同じものですからどの単位で測定してもいい訳です。 同様に体重を測定するときもそうです。キログラムで測ってもいいですし、グラムでも、あるいはトンや貫で測ってもいい訳です。 さて、厄介なのはこれら複数の測定単位がからみ合う時です。図2をご覧下さい。 この左上の図は、四つの点がそれぞれ大体同じぐらいの距離を保っているように見えます。 つまり、これらの四つの点を二つのグループに分けようとしても分け方に困るような位置関係にあります。 しかし、例えば横軸(X軸)を0.2倍してみます(つまり1/5に縮少します)。それが右上の図です。 そうすると、これは明らかに四つの点が上と下の二つのグループに分割できるでしょう。 さて、今度は逆に縦軸(Y軸)を0.2倍してみます。その図が左下の図です。 するとどうですか、今度は四つの点が左と右の二つのグループに分割できるでしょう。 つまり、同じデータでも単に尺度を変更するだけで、違った分割・分類(クラスター)になってしまうのです。 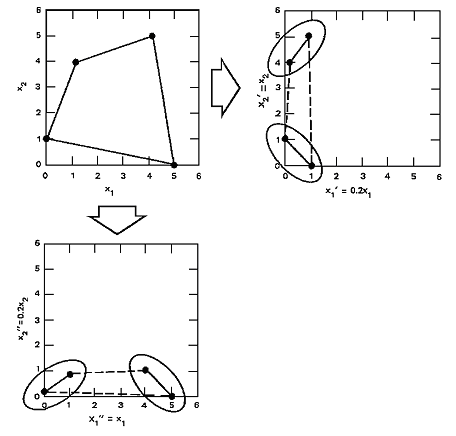 <図2:尺度をかえると別のグループに見える> データマイニングでは、事前のデータ分析にこのようにデータを分類する(これをクラスタリングと言います)ことをよく行います。 この時、測定単位(尺度)の取り方や一見科学的な正規化が逆に問題を引き起こすことがあります。そのことについて考えてみましょう。 データ解析をしている人は、よく何気なく(あまり深く考えもせず)データの単位を揃えるために、『正規化』をします。 正規化とは、各データ項目の最大値と最小値をそれぞれ1、-1、あるいは1、0のように読み替えて、データの範囲を揃えることを言います。 このようにすると、確かにデータ分布自体は見やすいので一見科学的のように思えますが、実は思いもよらぬ結果を招くことがあります。 図3をご覧ください。この左図は、本来の尺度で測定した値でデータをプロットしたものです。 それを『科学的』観点から正規化した値でデータをプロットしたのが右図です。 この二つの図を比較して下さい。 左図では明らかにこのデータは二つのグループが存在していることが分かります。 ところが、右図のように正規化したプロット図では、データ点がごちゃっと一塊に集まっているように見え、二つのグループ(クラスター)に分類できることは明瞭には分からなくなってしまいました。 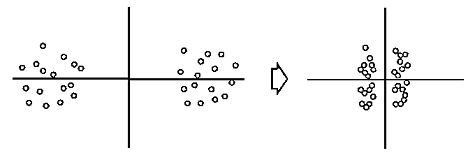 <図3:正規化の功罪> 【コンピュータプログラムの陥穽(おとしあな)】 また、データのクラスタリング(グループ分け)の問題はこれだけには止まりません。 クラスタリングは通常コンピュータプログラムで行いますが、そのプログラムは必ずしも人間が望むような分け方をしてくれません。図4をご覧下さい。 上のようにデータ点がプロットされていれば、誰でもこれは二つのグループに分類できると考えるでしょう。つまり、左下図のような分類を考えるでしょう。 そして、コンピュータプログラムも同じようにしてくれるはず、と期待するのではないでしょうか? しかし、コンピュータプログラムが考える分類とは、右下図なのです! 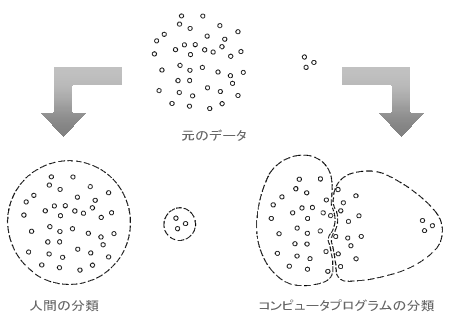 <図4:コンピュータプログラムと人間の分類基準の差> なぜ、こんなへんちくりんな分割になるの?と不思議に思われるかもしれませんが、これはコンピュータプログラム(アルゴリズム)が持っている分類の基準、『データの各点と代表点(中心点)の距離の総和を最小化する』を杓子定規に適用したからに他なりません。 このような分割結果を見て、『それは分類の基準がおかしいからだ。正しい分類基準に従えば、コンピュータだって正しい分割ができるはずだ。』と考えるでしょう。 それでは、次にコンピュータプログラムで異なった分類基準に従って、異なった分割結果を得るという例を示しましょう。 図5-1をご覧下さい。ここには三つの図が挙げてあります。 これらのデータ点に対して、二つの異なった分類基準(nearest-neighborアルゴリズムとfurthest-neighborアルゴリズム)でどういう分割・分類がなされるかを見てみましょう。 それぞれの結果を図5-2と図5-3に示します。 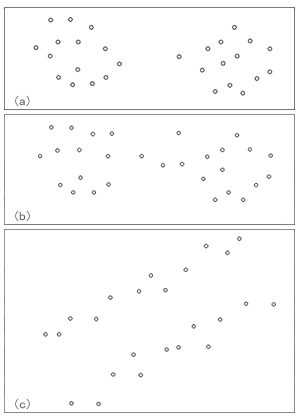 <図5-1:コンピュータプログラムの分類基準の差(元データ)> 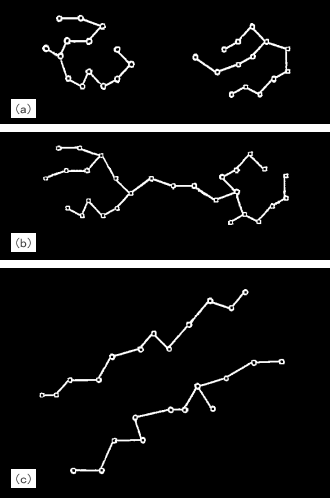 <図5-2:nearest-neighborアルゴリズムによる分割結果> 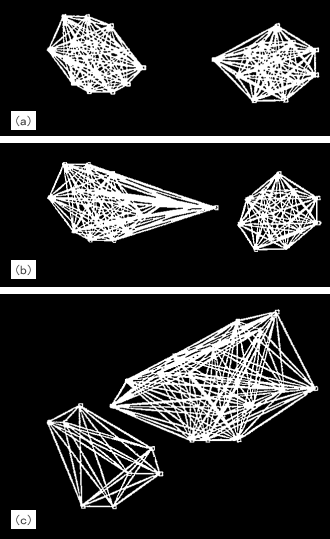 <図5-3:furthest-neighborアルゴリズムによる分割結果> この二つのコンピュータプログラムの図を見て分かりますように、人間が思ったような分割が行われる時もあれば、そうでない時もあることが分かります。 つまり、コンピュータプログラムで計算したから正しい結果が得られているはず、というのはあくまでも数学的観点であって、人間が考える観点ではないのです。 【結言】 私達が図によって理解できる範囲は、せいぜい二次元(平面)か三次元(立体)ですが、統計的手法やデータマイニングが対象とする次元はそういった低次元に留まりません。 何十次元(入力項目が何十もある場合)にもなると、どういったことがコンピュータプログラム内部で行われているか確認のしようがありません。 それで、出てきた結果を信用するしかないと考えがちですが、高次元でのデータ解析でも基本的には、私達が理解できる低次元の場合と同様のことがプログラムでは行われています。 従って、低次元の世界で人間の感覚的におかしいと思うことは実は高次元の世界でも、しばしば発生していることなのです。 要は、コンピュータから出てきた結果は盲信してはいけない、ということです。 人間の感覚でおかしいと感じたら、データを層別して再度分析する、あるいは、分類基準(つまりアルゴリズム)を変更して再度解析する、といった柔軟な態度がデータの蜃気楼に迷わない為には肝要なことなのです。 |
|
| 続く... |
|
|
△TOPへ Copyright © 2004 Zetta Technology Inc. All rights reserved.
|
|