【第28回】データマイニング・夜話
(その十:子供の頃わくわくした事)
コラムTOPへ戻る
|
|
|
|
|
【第28回】データマイニング・夜話 (その十:子供の頃わくわくした事) コラムTOPへ戻る |
|
| マーケティングの分野では従来から、優良顧客を見つける手法としてRFM法がよく使われています。RFM法というのを一口で言えば、『馴染み客を見つける方法』といえるでしょう。RFM手法の根本にある考え方(むしろ思い込みと言ったほうがいいかもしれませんが)は『過去に自分達の商品を買ってくれた人は将来もまた買ってくれるはずだ。過去に何度も買って馴染みになった客は、一見さんより買ってくれそうだ』と言うものです。 普通の店では馴染み客は顔を覚えていますので、店員は一見さんとすぐに区別がつきますが、データで処理するときはどうすればいいのでしょうか?RFMは馴染み客というのを次の3つの指標で見つけようとしています。 R = Recency(最近いつ買ってくれたか?) F = Frequency(過去何回買ってくれたか?) M = Monetary(過去に累積で何円買ってくれたか?) それぞれの指標について次のような考えに基づいて重み付けをします。 R :直近に買ってくれた人の方が昔に買ってくれた人より高いポイントを与える F :過去頻度多く買ってくれた人の方が頻度少なく買ってくれた人より高いポイントを与える M :過去累積で多額の金額を支払ってくれた人の方が少ない人より高いポイントを与える このような考えが妥当かどうかはひとまず横において、次のような3つのテーブルを作成しましょう。 表1:RFMのそれぞれのテーブル
これらのテーブルというのは、自分達の販売経験に照らして自社製品を買ってくれた中でどのような客が将来的にも引き続き買ってくれるかを得点にしたものです。この時、それぞれのテーブルの値はセールスに携わっている人達が集まり、あるいはアンケートを取って、かなり主観的に決められることが多いようです。と言うのは各テーブルの値の範囲の決め方や、その範囲に対するポイントの値の決め方に客観的な方法が存在しないからです。 何はともあれ、この3つの表ができたと仮定しましょう。 次はこれら3つの表を使ってどのように見込み客を見つけるかという活用の仕方を説明しましょう。 顧客の過去の購入履歴データをチェックします。 表2:顧客の購買履歴データ---10月1日現在 (単位:千円)
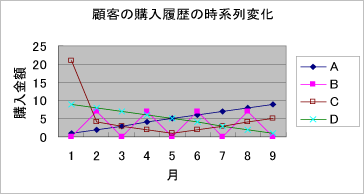
1月から9月までの9ヶ月間のデータから顧客Aから顧客Dまでの4人のRFMを計算してみましょう。 そのためには、それぞれのR、F、M、の値を別々に計算します。RFM値はこれら3つの合計値です。 表3:顧客のRFM値---10月1日現在
この結果からRFM値の最も高い顧客Dが見込み客となります。つまり次回最も買ってくれそうな人と言うことです。次いで顧客A、顧客C、顧客Bの順となります。 どうですか?RFMというのは簡単で誰でも使いこなせそうな手法だと思いませんか?実際、この簡便さのおかげで流通業界では従来から非常によく使われています。市販のデータベースマーケティングの本などでは必ずと言っていいほど推奨されている方法です。簡単で、しかも見込み客を確実に見つけてくれるなら問題ないはずですが実はRFM法(一般的には得点法と言われています)には長所とともにいろいろな欠点もあります。長所と短所をまとめますと: RFM法(得点法)の長所と短所 【長所】 1.各項目の各カテゴリーについて任意にかつ独立に重み付けができる。また変更も容易。 2.業務経験が点数として数量的に反映できる。 3.計算量が少ない。 2.重みの決め方に客観的な根拠がない。 3.既存テーブルを変更する際にどの項目をどのように修正すればよいのかが分からない。
おやおや、顧客A、顧客C、顧客Dの3人のRFM値はどれも同じ(56)になりますね。そうすると3人の購買意欲、購買動向は全く異なるにも拘わらずRFM値から見ると3人は全く同じグループに属すと見なされてしまうのです!このことはとりも直さずRFMの値で分類するというのは必ずしもマーケティング的に均質の顧客を集めることにはなっていないことを物語っています。 この欠陥はどのようにすれば直せるのでしょうか?残念ながら、RFM自体にはそれを直す方法はありません。データマイニングの観点に立てば、トレンドをパターン化してそれぞれの顧客に別々のカテゴ リー値を割り当てるということが考えられます。実際私は過去に通販の顧客の購買データを時系列的に分析し、幾つかのパターンを見つけて次期の購買予測の入力データ項目とし、かなり精度の高い モデルを作ることに成功した経験があります。 結局RFM法は計算量は少なく計算の仕組み自体は簡便なのですが、コンピュータを駆使して高精度の予測モデルをニューロなどのデータマイニング手法で容易に作れる現代においては、時代遅れのデータモデリング手法であると私は考えています。 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
続く... |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
△TOPへ Copyright © 2006 Zetta Technology Inc. All rights reserved.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||