

【第28回】データマイニング・夜話
(その十:子供の頃わくわくした事)
コラムTOPへ戻る
|
|
|
|
|
【第28回】データマイニング・夜話 (その十:子供の頃わくわくした事) コラムTOPへ戻る |
|
| 前回は、ニューロ(ニューラルネットワーク)は脳の情報処理の原理・しくみのまねをして作られたアルゴリズム(考え方)だと説明しました。
私たちの脳は、単に視覚や聴覚からの情報を認識するだけでなく、記憶したり、新たに考えたりすることができます。その際に基本になるのが、『学習』というプロセスです。つまり、誰でも初めから正解は分からないですから正解に至るために試行錯誤を繰り返すことになります。 これが学習プロセスと呼ばれていることなのです。脳の機能をまねたニューロも実はこの学習機能を持っています。この学習機能という点がニューロと他のソフトウェアとが大いに異なる点です。つまり、通常のソフトウェアというのは、処理の仕方(アルゴリズム)がプログラムに固定的に組み込まれていますので、状況に柔軟に対応することができません。 今回は学習プロセスについて考えてみましょう。 ところで、皆さんは備前岡山の湯浅常山という人によって書かれた常山紀談(じょうざんきだん)という本をご存知でしょうか。戦国時代や常山が生きていた江戸初期の武士にまつわるエピソードが数多く載せられています。 この中の一節をご紹介しましょう。信長が上洛した折、京料理の名人・坪内某に料理を作るよう命じました。しかし作った料理が代々貴族であった三好家に合わせた味だったので信長が水臭いと怒り、危うく殺されかけました。名コックの坪内は大慌てで、もう一回だけチャンスが欲しいと願い出ました。翌日はずっと味を落とし、塩辛〜い田舎風の味付けにして信長に大いに気にいられたという話で す。 この坪内コックは信長の気にいられるようにするため、料理の味付けを学習によって変えたわけですが、ニューロでは次のような考えでこの学習プロセスを実現しています。 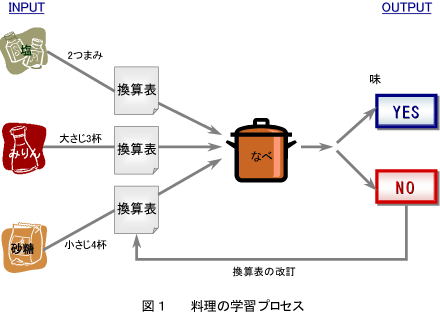 例えば、塩、みりん、砂糖を使って味をつけるとしましょう。通常、料理にはそれぞれのレシピーがあり、調味料の量が記載されています。例えば、塩(2つまみ)、みりん(大さじ3杯)、砂糖(小さじ4杯)などです。このレシピーを使って、先ほどの坪内コックは水臭いといわれたのです。つまり、アウトプットがNOであった訳です。それで、レシピーを変えずに内部の換算表を変えます。つまり、塩ひとつまみに該当する量を従来の2グラムから10グラムに変えたとします。そうすると、2つまみで4グラムから20グラム、つまり16グラム増量した訳です。その結果、アウトプットがYESになったという次第でした。 このように、換算表の内容を書き換えると同じレシピーでも味は変化する訳です。これをもう少し敷衍(ふえん)してみましょう。 例えば、ある料理学校に審査員が10人いたとします。生徒達は料理の味をテストされています。生徒はまず自分の味付けに従って、料理をつくります。調味料は同じく3つ(塩、みりん、砂糖)に限定 されているとしましょう。出来た料理を審査員が試食します。10人の審査員は、○(YES・うまい)と×(NO・まずい)の判断を示すだけです。つまり、審査員からは、どうまずいのか、あるいはどの調味料を増量せよとか、減量せよ、などと教えてもらえません。 但し、やり直しは何回でも許してもらえるとします。さて、生徒はこのYES/NOの判断だけで果たしてうまい料理を作ることができるでしょうか? 例えば、オットセイなどが餌に釣られて芸を覚える時のことを考えてください。オットセイはボール乗りができなかった時に正しい仕方を教えてもらうのではなく、単によくできたか(餌がもらえる)かできなかったか(餌がもらえない)かの結果を教えてもらえるだけですね。オットセイ自身はこの結果から、どうしたらうまくボールに乗れるかを自分自身で考えています。 オットセイでもできるのですから、人間でも同じような考えで結果だけから学べるはずです!今回の料理の場合には、次のようにすればどうでしょう。まず初めはそれぞれの調味料を少しだけ入れます 。まずいという評価であれば、それぞれの量をすこしだけ変えます。つまり、調味量を増加するか、または、水を入れて薄めます。そして、『うん、こっちの方がよくなった』と言われたら、その調味料を更に増やす、あるいは更に減らす方に修正し、最終的になるべく多くの審査員が美味いというまで量を調整します。このように、最初から味を決め打ちで作るのではなく、何度も繰り返して、出た結果に対する評価をもとにして内部変換表を修正することで段々と出力(今回の場合は料理の腕前)を改善していくことが、ニューロでいう学習プロセスなのです。 しかしここで一つ問題があります。美味いと言われた料理の味付けは異なる生徒で全く同じでしょうか?異なる味付けでも多くの審査員から高い評価を得るものもあるはずなのですね。これと同じこと がニューロの学習にも言えます。つまりニューロが出す結果(腕前)はなるべく多くの審査員に気に入ってもらう、という評価基準に基づいて換算表の内容を試行錯誤的に修正していますので、必ずしも換算表の内容は毎回同じにはなりません。さらに、複数の審査員がいる場合、特定の審査員に気にいる換算表を作ることも一般的には出来ません。 つまりニューロの学習結果は、特定のデータに対して、正しい答えをだせるかどうかでなく、なるべく多くのケースでYESをもらえるように調整するようになっているのです。 以上のように外部の結果のYES/NOの評価に基づいて換算表をすこしづつ修正する方法を数学用語では『最急降下法』と言います。この手法の主張する所は、『ある入力に対して、変換式を使って得られた出力が得点で評価されるなら、変換式を少しづつ変えることで得点を必ず向上させることができる』というものです。今回の料理の場合、得点とは、審査員の判定で、変換式というのが換算表ということになります。つまり、どんな料理の素人でも、審査員が(厭きることなく)判定を言ってくれるなら、味付けの腕前が必ず向上する、という事なのです! なぜ、このような事が可能か、『最急降下法』の仕組みを喩えを使って説明しましょう。 皆さんは濃霧の中を登山したことがありますか?濃い霧がかかっていると、足元も見えないことがありますね。ましてや、頂上がどこにあるのか見当すらつかない状況です。このような濃霧のなか、全 くの案内人なしに山の頂上を目指す事を考えてみてください。その山には高い木々は全くなく、どこも砂利ばかりの裸の山だとします。前人未踏の山なので、道は全くないとしましょう。おまけに濃霧です。(実際問題として、そのような山を登るか?という疑問はありますが。。。) さて、山の頂上を目指すには、自分が今居る所より高い地点を目指す必要がある訳ですね。しかし頂上は方角すらわからないです。このような時、どのようにすれば頂上にたどり着けるでしょうか? 単純な考えとして、もし一歩ごとに少しでも現在の所より高い地点に移動することを積み重ねていけば、段々高い所にいけるはず、と考えませんか? この方法を分解してみましょう。 1.自分の立っているところを起点として、半径1メーターの円を描く。 2.その円周の上の点で一番高い地点を見つける。 3.その地点に移る。 4.もうこれ以上高い所は見えない、というまでこの1.から3.のプロセスを繰り返す。 この方法では、たとえ濃霧で山の頂上が見えなくても、少なくとも徐々に高い地点に進んでいくことになり(運が良ければ!)最終的には頂上に辿りつくことができます。 ここで頂上と麓をさかさまにしてみますと、一番急な坂を登ると言うのは、一番急な坂を降りていくことに該当することが分かるでしょう。これが、最急降下法と呼ばれるゆえんなのです。 しかし、この方法では途中でひょっこりと小さい丘の上(偽の頂上)に迷いこんでしまうこともあり得ます。つまりこの方法は必ずしも頂上に到達できることを保証してくれません。料理で言うと、素人がはじめに作った味よりは確実に進歩するものの必ずしも一流のコックの腕前に到達するという保証はありません。しかしいづれにしても、出発地点よりは腕前、あるいはデータマイニングでいうと正答率が改善されていることは間違いありません。 結局、ニューロの学習プロセスのキーポイントは次のようになります。 『結果が評点で示されるなら、評点が高くなるように内部変換表を少しだけ変える、 というプロセスを繰り返すだけで、腕前 (正当率)が必ず向上する。』 |
|
| 続く... |
|
|
△TOPへ Copyright © 2005 Zetta Technology Inc. All rights reserved.
|
|